Introduccion to MULTIVARIATE ANALYSIS
T. Monleon
DATA SCIENCE POSTDEGREE 2020
- Introduccion to MULTIVARIATE ANALYSIS
- Dimension reduction
- Datos geoespaciales y mapas
- Un ejercicio final de analisis multivariante exploratorio
- Un segundo ejercicio final de analisis multivariante
- Exploracion con datos geoestadisticos
- Analisis con redes complejas (Network analysis)
- Categorical variables
Introduccion to MULTIVARIATE ANALYSIS
Unos libros recomendados:
Exploratory Data Analysis with R Roger D. Peng 2016-09-14 https://bookdown.org/rdpeng/exdata/
Inline-style: 
An example of statistical data analysis using the R environment for statistical computing: http://www.css.cornell.edu/faculty/dgr2/teach/R/R_corregr.pdf
Un curso y un caso de estudio:
https://bookdown.org/rdpeng/exdata/the-ggplot2-plotting-system-part-1.html#case-study-maacs-cohort
Un ejemplo motivador:
Existen de muchos tipos de analisis y graficos multivariantes, aunque son complejos. Ver en https://www.r-graph-gallery.com/boxplot/
#Scatter plot with circles
#mayor a mayor diametro del circulo
a=seq(1:100) + 0.1*seq(1:100)*sample(c(1:10) , 100 , replace=T)
b=seq(1:100) + 0.2*seq(1:100)*sample(c(1:10) , 100 , replace=T)
plot(a,b , xlim=c(10,200) , ylim=c(10,200) , pch=20 , bg="white" , cex=3+(a/30) , col=rgb(a/300,b/300,0.9,0.9) )
Otro ejemplo utilizado en genomica son los Manhattan plots A Manhattan plot is a particular type of scatterplot used in genomics. The X axis displays the position of a genetic variant on the genome. Each chromosome is usually represented using a different color. The Y axis shows p-value of the association test with a phenotypic trait.
The CMplot library by Lilin Yin is a good choice if you want to make a circular version of your manhattanplot. I believe than doing a circular version makes sense: it gives less space to all the non significant SNPs that do not interest us, and gives more space for the significant association. Moreover, the CMplot makes their realization straightforward.
library("CMplot") #install.packages("CMplot")
library(qqman) #install.packages("qqman")
CMplot(gwasResults, plot.type="c", r=1.6, cir.legend=TRUE,
outward=TRUE, cir.legend.col="black", cir.chr.h=.1 ,chr.den.col="orange", file="jpg",
memo="", dpi=300, chr.labels=seq(1,22))## Circular-Manhattan Plotting P.
## Plots are stored in: C:/Users/bootstrap3/Dropbox/Data Science R and Python 2018-2020/Presentaciones/Sesion MULTIVARIANTE Imanhattanplot type 1:
Inline-style: 
manhattanplot type 2 (advanced):
Inline-style: 
Correlation and scatterplot
Correlation and dependence:
From Wikipedia, the free encyclopedia
See at https://en.wikipedia.org/wiki/Correlation_and_dependence
This article is about correlation and dependence in statistical data. For other uses, see correlation (disambiguation). In statistics, dependence or association is any statistical relationship, whether causal or not, between two random variables or bivariate data. Correlation is any of a broad class of statistical relationships involving dependence, though in common usage it most often refers to how close two variables are to having a linear relationship with each other. Familiar examples of dependent phenomena include the correlation between the physical statures of parents and their offspring, and the correlation between the demand for a limited supply product and its price.
#correlagrama que indique grado de relacion y
#direccion de la relacion
# Libraries
library(ellipse)
library(RColorBrewer)
# Use of the mtcars data proposed by R
data=cor(mtcars)
# Build a Pannel of 100 colors with Rcolor Brewer
my_colors <- brewer.pal(5, "Spectral")
my_colors=colorRampPalette(my_colors)(100)
# Order the correlation matrix
ord <- order(data[1, ])
data_ord = data[ord, ord]
plotcorr(data_ord , col=my_colors[data_ord*50+50] , mar=c(1,1,1,1) )
Correlations are useful because they can indicate a predictive relationship that can be exploited in practice. For example, an electrical utility may produce less power on a mild day based on the correlation between electricity demand and weather. In this example, there is a causal relationship, because extreme weather causes people to use more electricity for heating or cooling. However, in general, the presence of a correlation is not sufficient to infer the presence of a causal relationship (i.e., correlation does not imply causation).
Formally, random variables are dependent if they do not satisfy a mathematical property of probabilistic independence. In informal parlance, correlation is synonymous with dependence. However, when used in a technical sense, correlation refers to any of several specific types of relationship between mean values. There are several correlation coefficients, often denoted \(\rho\) or r, measuring the degree of correlation. The most common of these is the Pearson correlation coefficient, which is sensitive only to a linear relationship between two variables (which may be present even when one variable is a nonlinear function of the other). Other correlation coefficients have been developed to be more robust than the Pearson correlation \(\rho\) that is, more sensitive to nonlinear relationships. Mutual information can also be applied to measure dependence between two variables.
How to measure the linear correlation:
\[ {\displaystyle \rho _{X,Y}=\mathrm {corr} (X,Y)={\mathrm {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}={E[(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}},} \rho _{X,Y}=\mathrm {corr} (X,Y)={\mathrm {cov} (X,Y) \over \sigma _{X}\sigma _{Y}}={E[(X-\mu _{X})(Y-\mu _{Y})] \over \sigma _{X}\sigma _{Y}} \]
where E is the expected value operator, cov means covariance, and corr is a widely used alternative notation for the correlation coefficient.
A diagram of correlation and \(\rho\):
Inline-style: 
(From Wikipedia)
The Pearson correlation is defined only if both of the standard deviations are finite and nonzero. It is a corollary of the Cauchy-Schwarz inequality that the correlation cannot exceed 1 in absolute value. The correlation coefficient is symmetric: corr(X,Y) = corr(Y,X).
The Pearson correlation is +1 in the case of a perfect direct (increasing) linear relationship (correlation), = 1 in the case of a perfect decreasing (inverse) linear relationship (anticorrelation), and some value in the open interval (-1, 1) in all other cases, indicating the degree of linear dependence between the variables. As it approaches zero there is less of a relationship (closer to uncorrelated). The closer the coefficient is to either -1 or 1, the stronger the correlation between the variables.
If the variables are independent, Pearson’s correlation coefficient is 0, but the converse is not true because the correlation coefficient detects only linear dependencies between two variables. For example, suppose the random variable X is symmetrically distributed about zero, and Y = X2. Then Y is completely determined by X, so that X and Y are perfectly dependent, but their correlation is zero; they are uncorrelated. However, in the special case when X and Y are jointly normal, uncorrelatedness is equivalent to independence.
If we have a series of n measurements of X and Y written as xi and yi for i = 1, 2, …, n, then the sample correlation coefficient can be used to estimate the population Pearson correlation r between X and Y. The sample correlation coefficient is written as
\[ {\displaystyle r_{xy}={\frac {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{(n-1)s_{x}s_{y}}}={\frac {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{\sqrt {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})^{2}\sum \limits _{i=1}^{n}(y_{i}-{\bar {y}})^{2}}}},} {\displaystyle r_{xy}={\frac {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{(n-1)s_{x}s_{y}}}={\frac {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}{\sqrt {\sum \limits _{i=1}^{n}(x_{i}-{\bar {x}})^{2}\sum \limits _{i=1}^{n}(y_{i}-{\bar {y}})^{2}}}},} \]
where x and y are the sample means of X and Y, and sx and sy are the corrected sample standard deviations of X and Y.
Non parametric correlation (Spearman and Kendall)
Is possible measure the correlation between variables that follow a Gaussian distribution with the Pearson product-moment correlation coefficient. If it is not possible to assume that the values follow gaussian distributions, we have two non-parametric methods: the Spearman s rho test and Kendall s tau test (see https://www.r-bloggers.com/non-parametric-methods-for-the-study-of-the-correlation-spearmans-rank-correlation-coefficient-and-kendall-tau-rank-correlation-coefficient/)
Inline-style: 
For example, you want to study the productivity of various types of machinery and the satisfaction of operators in their use (as with a number from 1 to 10). These are the values:
Productivity: 5, 7, 9, 9, 8, 6, 4, 8, 7, 7 Satisfaction: 6, 7, 4, 4, 8, 7, 3, 9, 5, 8
Begin to use first the Spearman’s rank correlation coefficient:
Productivity<- c(5, 7, 9, 9, 8, 6, 4, 8, 7, 7)
Satisfaction<- c(6, 7, 4, 4, 8, 7, 3, 9, 5, 8)
cor.test(Productivity, Satisfaction, method="spearman")##
## Spearman's rank correlation rho
##
## data: Productivity and Satisfaction
## S = 146, p-value = 0.8
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.1153The statistical test gives us as a result rho = 0.115, which indicates a low correlation (not parametric) between the two sets of values. The p-value > 0.05 makes us not accept the value of rho calculated as being statistically significant.
cor.test(Productivity, Satisfaction, method="kendall")##
## Kendall's rank correlation tau
##
## data: Productivity and Satisfaction
## z = 0.56, p-value = 0.6
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## 0.1464Also with the Kendall test, the correlation is very low (tau = 0.146), and not-significant (p-value > 0.05).
A real example (https://rcompanion.org/rcompanion/e_02.html)
### --------------------------------------------------------------
### Spearman rank correlation, species diversity example
### p. 214
### --------------------------------------------------------------
Input = ("
Town State Latitude Species
'Bombay Hook' DE 39.217 128
'Cape Henlopen' DE 38.800 137
'Middletown' DE 39.467 108
'Milford' DE 38.958 118
'Rehoboth' DE 38.600 135
'Seaford-Nanticoke' DE 38.583 94
'Wilmington' DE 39.733 113
'Crisfield' MD 38.033 118
'Denton' MD 38.900 96
'Elkton' MD 39.533 98
'Lower Kent County' MD 39.133 121
'Ocean City' MD 38.317 152
'Salisbury' MD 38.333 108
'S Dorchester County' MD 38.367 118
'Cape Charles' VA 37.200 157
'Chincoteague' VA 37.967 125
'Wachapreague' VA 37.667 114
")
Data = read.table(textConnection(Input),header=TRUE)
plot(Species ~ Latitude,
data=Data,
pch=16)
cor.test( ~ Species + Latitude,
data=Data,
method = "spearman",
continuity = FALSE,
conf.level = 0.95)##
## Spearman's rank correlation rho
##
## data: Species and Latitude
## S = 1112, p-value = 0.2
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## -0.3626Partial correlation
Inline-style: 
Partial correlation is the correlation of two variables while controlling for a third or more other variables. There are two methods to compute the partial correlation coefficient in pcor.test. One is by using variance-covariance matrix (“mat”) and the other recursive formula (“rec”). Both of “mat” and “rec” give the same result in case of na.rm = T. Otherwise, the estimate may be slightly different from each other due to the way dealing with the missing samples, if there are the missing samples.
The partial correlation is solved by:
Inline-style: 
# load the R code "pcor.test"
library(ppcor)
# data
y.data <- data.frame(
hl=c(7,15,19,15,21,22,57,15,20,18),
disp=c(0.000,0.964,0.000,0.000,0.921,0.000,0.000,1.006,0.000,1.011),
deg=c(9,2,3,4,1,3,1,3,6,1),
BC=c(1.78e-02,1.05e-06,1.37e-05,7.18e-03,0.00e+00,0.00e+00,0.00e+00,4.48e-03,2.10e-06,0.00e+00)
)
# partial correlation between "hl" and "disp" given "deg" and "BC"
pcor.test(y.data$hl,y.data$disp,y.data[,c("deg","BC")])pcor.test(y.data[,1],y.data[,2],y.data[,c(3:4)])pcor.test(y.data[,1],y.data[,2],y.data[,-c(1:2)])Scatter plot and correlation
To measure the relationship within multiple variables we can use a scatterplot graph.
Basic Scatterplot Matrix
# Enhanced Scatterplot of MPG vs. Weight
# Simple Scatterplot
attach(mtcars)
plot(wt, mpg, main="Scatterplot Example",
xlab="Car Weight ", ylab="Miles Per Gallon ", pch=19)
# Basic Scatterplot Matrix
pairs(~mpg+disp+drat+wt,data=mtcars,
main="Simple Scatterplot Matrix")
#correlations on the pairs
# Customize upper panel
upper.panel<-function(x, y){
points(x,y, pch=19, col=c("red", "green3", "blue")[iris$Species])
r <- round(cor(x, y), digits=2)
txt <- paste0("R = ", r)
usr <- par("usr"); on.exit(par(usr))
par(usr = c(0, 1, 0, 1))
text(0.5, 0.9, txt)
}
pairs(iris[,1:4], lower.panel = NULL,
upper.panel = upper.panel)
uso del paquete psych
library(psych)
pairs.panels(iris[,-5],
method = "pearson", # correlation method
hist.col = "#00AFBB",
density = TRUE, # show density plots
ellipses = TRUE # show correlation ellipses
)
Other graphics of correlation at:
http://www.sthda.com/english/wiki/visualize-correlation-matrix-using-correlogram
Ejemplo de otros graficos de correlacion
#CIRCULAR PLOT: CIRCLIZE PACKAGE (2)
#Create data
name=c(3,10,10,3,6,7,8,3,6,1,2,2,6,10,2,3,3,10,4,5,9,10)
feature=paste("feature ", c(1,1,2,2,2,2,2,3,3,3,3,3,3,3,4,4,4,4,5,5,5,5) , sep="")
dat <- data.frame(name,feature)
dat <- with(dat, table(name, feature))
# Charge the circlize library
library(circlize)
# Make the circular plot
chordDiagram(as.data.frame(dat), transparency = 0.5)
Dimension reduction
ejemplo con
See at https://bookdown.org/rdpeng/exdata/dimension-reduction.html#matrix-data
set.seed(12345)
dataMatrix <- matrix(rnorm(400), nrow = 40)
image(1:10, 1:40, t(dataMatrix)[, nrow(dataMatrix):1])
Datos geoespaciales y mapas
Muchos ejemplos pueden encontrarse en este curso
https://geocompr.robinlovelace.net/intro.html
library(leaflet)
popup = c("Robin", "Jakub", "Jannes")
leaflet() %>%
addProviderTiles("NASAGIBS.ViirsEarthAtNight2012") %>%
addMarkers(lng = c(-3, 23, 11),
lat = c(52, 53, 49),
popup = popup)Other example of animated map is:
https://geocompr.robinlovelace.net/figures/urban-animated.gif
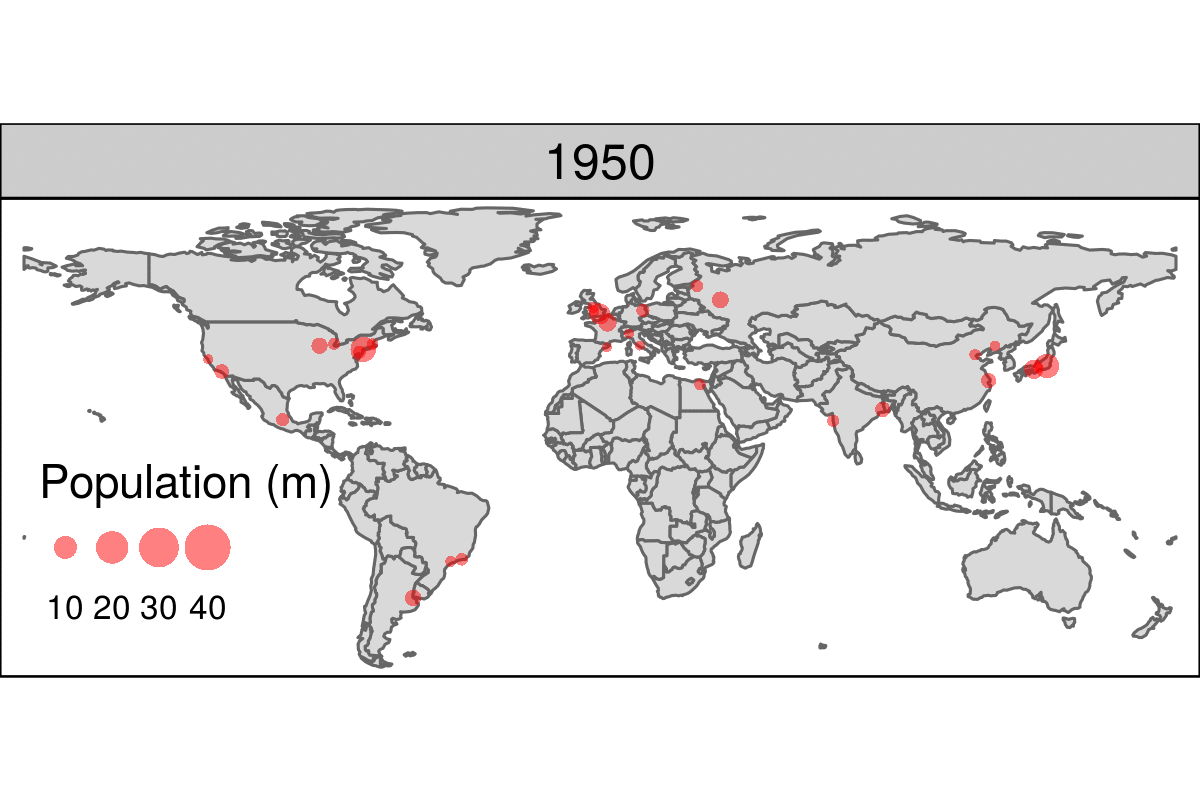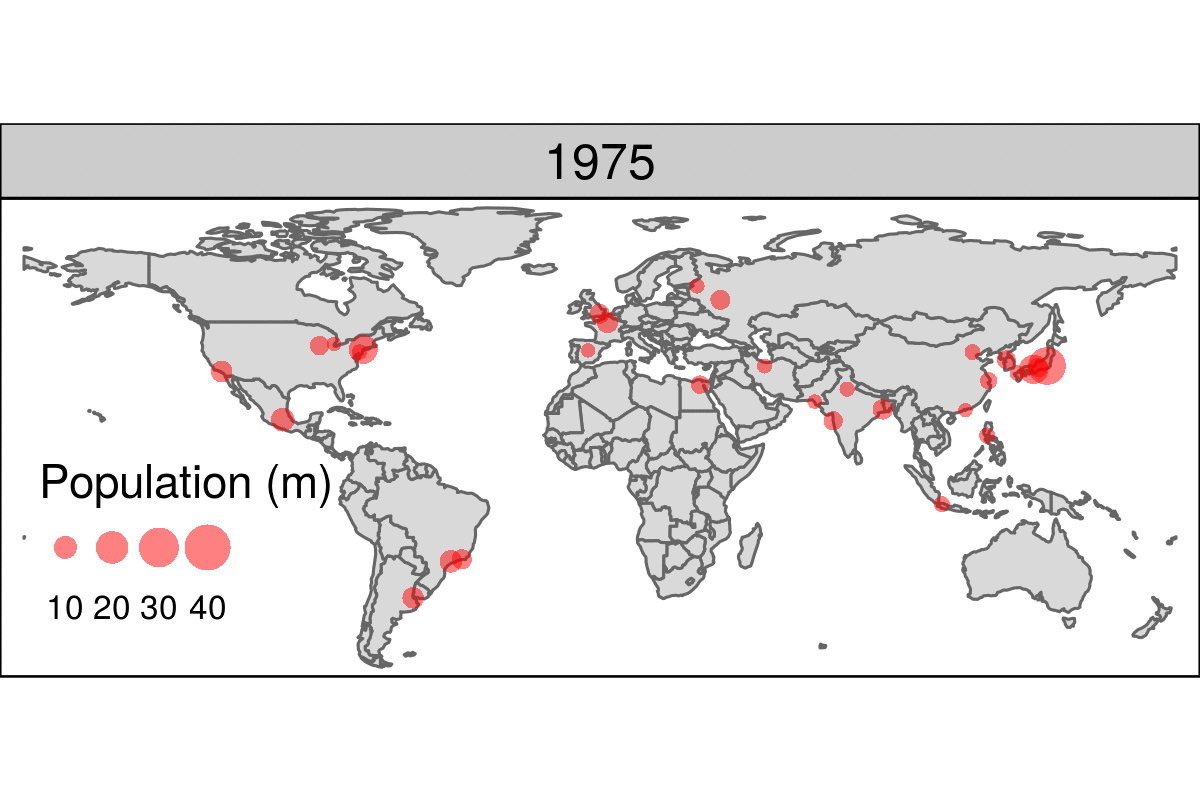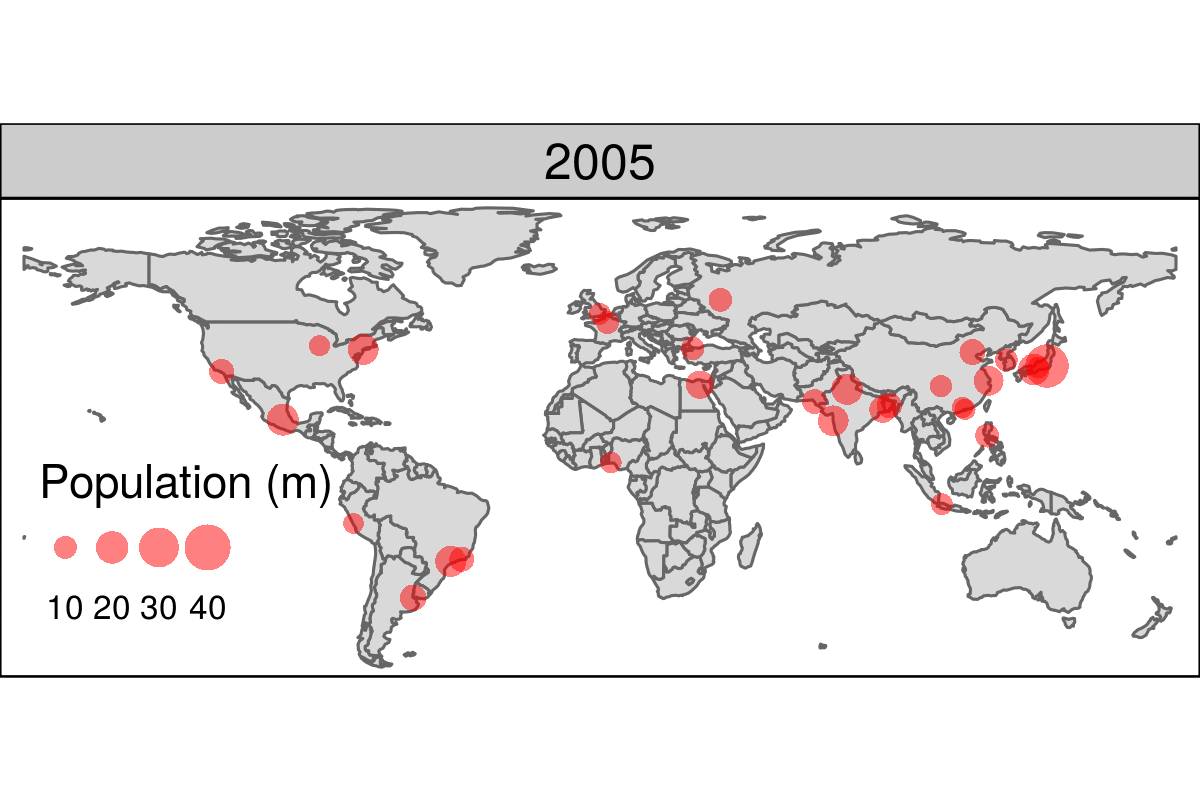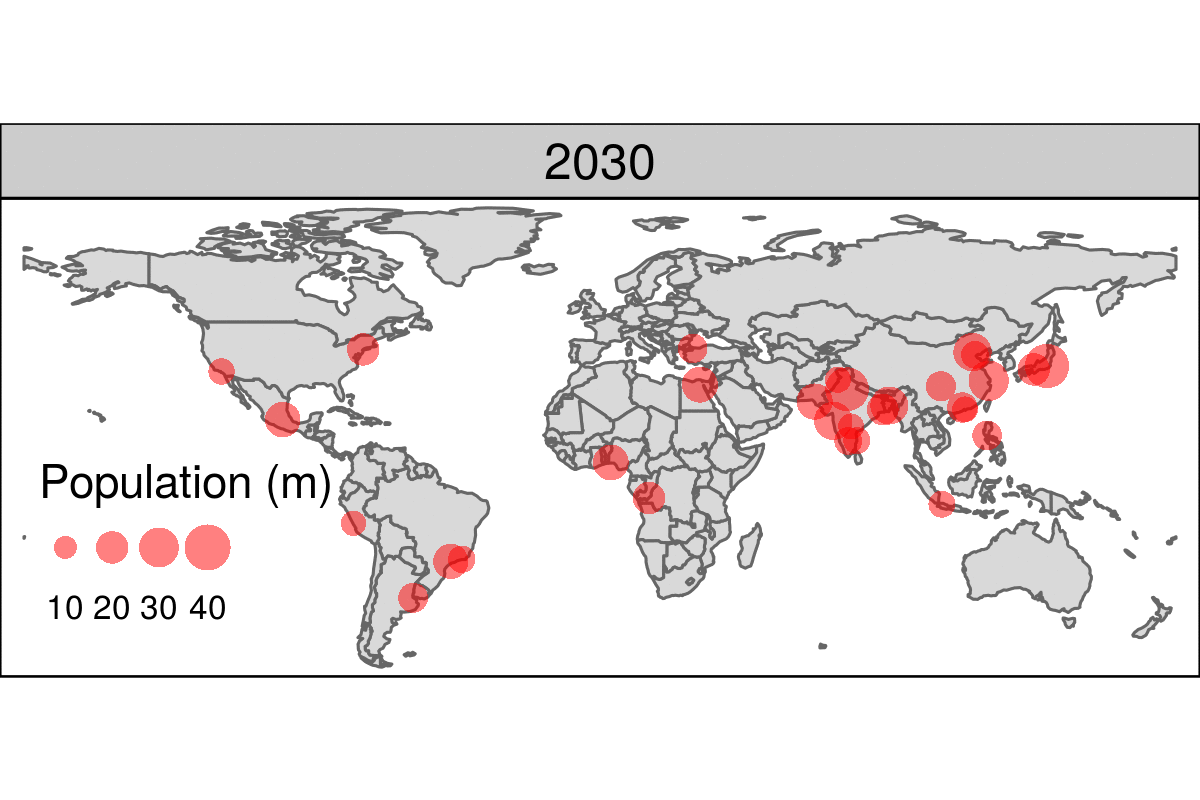{kind=link}
More examples at:
https://geocompr.robinlovelace.net/adv-map.html#animated-maps
Un ejercicio final de analisis multivariante exploratorio
A Little Book of R For Multivariate Analysis
Avril Coghlan
For example, the file http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data contains data on concentrations of 13 different chemicals in wines grown in the same region in Italy that are derived from three different cultivars.
Inline-style: 
There is one row per wine sample. The first column contains the cultivar of a wine sample (labelled 1, 2 or 3), and the following thirteen columns contain the concentrations of the 13 different chemicals in that sample. The columns are separated by commas.
When we read the file into R using the read.table() function, we need to use the “sep=” argument in read.table() to tell it that the columns are separated by commas. That is, we can read in the file using the read.table() function as follows:
wine <- read.table("http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",
sep=",")
head(wine)Inline-style: 
A Matrix Scatterplot One common way of plotting multivariate data is to make a “matrix scatterplot”, showing each pair of variables plotted against each other. We can use the “scatterplotMatrix()” function from the “car” R package to do this. To use this function, we first need to install the “car” R package (for instructions on how to install an R package, see How to install an R package). Once you have installed the “car” R package, you can load the “car” R package by typing:
library("car")You can then use the “scatterplotMatrix()” function to plot the multivariate data. To use the scatterplotMatrix() function, you need to give it as its input the variables that you want included in the plot. Say for example, that we just want to include the variables corresponding to the concentrations of the first five chemicals. These are stored in columns 2-6 of the variable “wine”. We can extract just these columns from the variable “wine” by typing
head(wine[2:6])To make a matrix scatterplot of just these 13 variables using the scatterplotMatrix() function we type:
scatterplotMatrix(wine[2:6])
In this matrix scatterplot, the diagonal cells show histograms of each of the variables, in this case the concentrations of the first five chemicals (variables V2, V3, V4, V5, V6). Each of the off-diagonal cells is a scatterplot of two of the five chemicals, for example, the second cell in the first row is a scatterplot of V2 (y-axis) against V3 (x-axis).
A Scatterplot with the Data Points Labelled by their Group If you see an interesting scatterplot for two variables in the matrix scatterplot, you may want to plot that scatterplot in more detail, with the data points labelled by their group (their cultivar in this case). For example, in the matrix scatterplot above, the cell in the third column of the fourth row down is a scatterplot of V5 (x-axis) against V4 (y-axis). If you look at this scatterplot, it appears that there may be a positive relationship between V5 and V4. We may therefore decide to examine the relationship between V5 and V4 more closely, by plotting a scatterplot of these two variable, with the data points labelled by their group (their cultivar). To plot a scatterplot of two variables, we can use the “plot” R function. The V4 and V5 variables are stored in the columns V4 and V5 of the variable “wine”, so can be accessed by typing wine\(V4 or wine\)V5. Therefore, to plot the scatterplot, we type
plot(wine$V4, wine$V5)
text(wine$V4, wine$V5, wine$V1, cex=0.7, pos=4, col="red")
We can see from the scatterplot of V4 versus V5 that the wines from cultivar 2 seem to have lower values of V4 compared to the wines of cultivar 1.
A Profile Plot Another type of plot that is useful is a “profile plot”, which shows the variation in each of the variables, by plotting the value of each of the variables for each of the samples. The function “makeProfilePlot()” below can be used to make a profile plot. This function requires the “RColor- Brewer” library. To use this function, we first need to install the “RColorBrewer” R package (for instructions on how to install an R package, see How to install an R package).
makeProfilePlot <-function(mylist,names){
require(RColorBrewer)
# find out how many variables we want to include
numvariables <-length(mylist)
# choose 'numvariables' random colours
colours <- brewer.pal(numvariables,"Set1")
# find out the minimum and maximum values of the variables:
mymin <- 1e+20
mymax <- 1e-20
for(i in 1:numvariables){
vectori <- mylist[[i]]
mini <-min(vectori)
maxi <-max(vectori)
if(mini < mymin) { mymin <- mini }
if(maxi > mymax) { mymax <- maxi }
}
# plot the variables
for(i in 1:numvariables){
vectori <- mylist[[i]]
namei <-names[i]
colouri <- colours[i]
if(i == 1) {
plot(vectori,col=colouri,type="l",ylim=c(mymin,mymax)) }
else
{ points(vectori, col=colouri,type="l") }
lastxval <-length(vectori)
lastyval <- vectori[length(vectori)]
text((lastxval-10),(lastyval),namei,col="black",cex=0.6)
}
}The arguments to the function are a vector containing the names of the varibles that you want to plot, and a list variable containing the variables themselves. For example, to make a profile plot of the concentrations of the first five chemicals in the wine samples (stored in columns V2, V3, V4, V5, V6 of variable “wine”), we type
library(RColorBrewer)
names <-c("V2","V3","V4","V5","V6")
mylist <-list(wine$V2,wine$V3,wine$V4,wine$V5,wine$V6)
makeProfilePlot(mylist,names)
It is clear from the profile plot that the mean and standard deviation for V6 is quite a lot higher than that for the other variables
Calculating Correlations for Multivariate Data It is often of interest to investigate whether any of the variables in a multivariate data set are significantly correlated.
To calculate the linear (Pearson) correlation coefficient for a pair of variables, you can use the “cor.test()” functionin R.
The function “mosthighlycorrelated()” will print out the linear correlation coefficients for each pair of variables in your data set, in order of the correlation coefficient. This lets you see very easily which pair of variables are most highly correlated.
mosthighlycorrelated<-function(mydataframe,numtoreport){
# find the correlations
cormatrix <- cor(mydataframe)
# set the correlations on the diagonal or lower triangle to zero,
# so they will not be reported as the highest ones:
diag(cormatrix) <- 0
cormatrix[lower.tri(cormatrix)] <- 0
# flatten the matrix into a dataframe for easy sorting
fm <-as.data.frame(as.table(cormatrix))
# assign human-friendly names
names(fm) <-c("First.Variable", "Second.Variable","Correlation")
# sort and print the top n correlations
head(fm[order(abs(fm$Correlation),decreasing=T),],n=numtoreport)
}
#For example, to calculate correlation coefficients between the concentrations of the 13 chemicals in the wine
#samples, and to print out the top 10 pairwise #correlation coefficients, you can type:
mosthighlycorrelated(wine[2:14], 10)This tells us that the pair of variables with the highest linear correlation coefficient are V7 and V8 (correlation = 0.86 approximately).
Standardising Variables If you want to compare different variables that have different units, are very different variances, it is a good idea to first standardise the variables. For example, we found above that the concentrations of the 13 chemicals in the wine samples show a wide range of standard deviations, from 0.1244533 for V9 (variance 0.01548862) to 314.9074743 for V14 (variance 99166.72). This is a range of approximately 6,402,554-fold in the variances. As a result, it is not a good idea to use the unstandardised chemical concentrations as the input for a principal component analysis (PCA, see below) of the wine samples, as if you did that, the first principal component would be dominated by the variables which show the largest variances, such as V14. Thus, it would be a better idea to first standardise the variables so that they all have variance 1 and mean 0, and to then carry out the principal component analysis on the standardised data. This would allow us to find the principal components that provide the best low-dimensional representation of the variation in the original data, without being overly biased by those variables that show the most variance in the original data. You can standardise variables in R using the “scale()” function. For example, to standardise the concentrations of the 13 chemicals in the wine samples, we type
standardisedconcentrations <-as.data.frame(scale(wine[2:14]))
sapply(standardisedconcentrations,mean)## V2 V3 V4
## -0.00000000000000085918 -0.00000000000000006776 0.00000000000000080452
## V5 V6 V7
## -0.00000000000000007720 -0.00000000000000004074 -0.00000000000000001396
## V8 V9 V10
## 0.00000000000000006958 -0.00000000000000010422 -0.00000000000000012214
## V11 V12 V13
## 0.00000000000000003649 0.00000000000000020937 0.00000000000000030035
## V14
## -0.00000000000000010344sapply(standardisedconcentrations,sd)## V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14
## 1 1 1 1 1 1 1 1 1 1 1 1 1We see that the means of the standardised variables are all very tiny numbers and so are essentially equal to 0, and the standard deviations of the standardised variables are all equal to 1
Principal Component Analysis https://es.wikipedia.org/wiki/An%C3%A1lisis_de_componentes_principales
The purpose of principal component analysis is to find the best low-dimensional representation of the variation in a multivariate data set. For example, in the case of the wine data set, we have 13 chemical concentrations describ- ing wine samples from three different cultivars. We can carry out a principal component analysis to investigate whether we can capture most of the variation between samples using a smaller number of new variables (prin- cipal components), where each of these new variables is a linear combination of all or some of the 13 chemical concentrations. To carry out a principal component analysis (PCA) on a multivariate data set, the first step is often to standardise the variables under study using the “scale()” function (see above). This is necessary if the input variables have very different variances, which is true in this case as the concentrations of the 13 chemicals have very different variances (see above).
Inline-style: 
Once you have standardised your variables, you can carry out a principal component analysis using the “prcomp()” function in R. For example, to standardise the concentrations of the 13 chemicals in the wine samples, and carry out a principal components analysis on the standardised concentrations, we type:
#prinCipal component analysis
standardisedconcentrations <-as.data.frame(scale
(wine[2:14]))
# standardise the variables
wine.pca <- prcomp(standardisedconcentrations)
# do a PCAYou can get a summary of the principal component analysis results using the “summary()” function on the output of “prcomp()”:
#results of the PCA
summary(wine.pca)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8
## Standard deviation 2.169 1.580 1.203 0.9586 0.9237 0.8010 0.7423 0.5903
## Proportion of Variance 0.362 0.192 0.111 0.0707 0.0656 0.0494 0.0424 0.0268
## Cumulative Proportion 0.362 0.554 0.665 0.7360 0.8016 0.8510 0.8934 0.9202
## PC9 PC10 PC11 PC12 PC13
## Standard deviation 0.5375 0.5009 0.4752 0.411 0.32152
## Proportion of Variance 0.0222 0.0193 0.0174 0.013 0.00795
## Cumulative Proportion 0.9424 0.9617 0.9791 0.992 1.00000This gives us the standard deviation of each component, and the proportion of variance explained by each component. The standard deviation of the components is stored in a named element called “sdev” of the output variable made by “prcomp”
#results of the PCA
wine.pca$sdev## [1] 2.1693 1.5802 1.2025 0.9586 0.9237 0.8010 0.7423 0.5903 0.5375 0.5009
## [11] 0.4752 0.4108 0.3215The total variance explained by the components is the sum of the variances of the components:
#results of the PCA
sum((wine.pca$sdev)^2)## [1] 13In this case, we see that the total variance is 13, which is equal to the number of standardised variables (13 variables). This is because for standardised data, the variance of each standardised variable is 1. The total variance is equal to the sum of the variances of the individual variables, and since the variance of each standardised variable is 1, the total variance should be equal to the number of variables (13 here)
#results of the PCA
sum((wine.pca$sdev)^2)## [1] 13Deciding How Many Principal Components to Retain In order to decide how many principal components should be retained, it is common to summarise the results of a principal components analysis by making a scree plot, which we can do in R using the “screeplot()” function:
screeplot(wine.pca, type="lines")
The most obvious change in slope in the scree plot occurs at component 4, which is the “elbow” of the scree plot. Therefore, it cound be argued based on the basis of the scree plot that the first three components should be retained. Another way of deciding how many components to retain is to use Kaiser’s criterion: that we should only retain principal components for which the variance is above 1 (when principal component analysis was applied to standardised data). We can check this by finding the variance of each of the principal components
(wine.pca$sdev)^2## [1] 4.7059 2.4970 1.4461 0.9190 0.8532 0.6417 0.5510 0.3485 0.2889 0.2509
## [11] 0.2258 0.1688 0.1034We see that the variance is above 1 for principal components 1, 2, and 3 (which have variances 4.71, 2.50, and 1.45, respectively). Therefore, using Kaiser’s criterion, we would retain the first three principal components. A third way to decide how many principal components to retain is to decide to keep the number of components required to explain at least some minimum amount of the total variance. For example, if it is important to explain at least 80% of the variance, we would retain the first five principal components, as we can see from the output of “summary(wine.pca)” that the first five principal components explain 80.2% of the variance (while the first four components explain just 73.6%, so are not sufficient)
Loadings for the Principal Components The loadings for the principal components are stored in a named element “rotation” of the variable returned by “prcomp()”. This contains a matrix with the loadings of each principal component, where the first column in the matrix contains the loadings for the first principal component, the second column contains the loadings for the second principal component, and so on
Therefore, to obtain the loadings for the first and second principal components in our analysis of the 13 chemical concentrations in wine samples, we type:
wine.pca$rotation[,1]## V2 V3 V4 V5 V6 V7 V8 V9
## -0.144329 0.245188 0.002051 0.239320 -0.141992 -0.394661 -0.422934 0.298533
## V10 V11 V12 V13 V14
## -0.313429 0.088617 -0.296715 -0.376167 -0.286752wine.pca$rotation[,2]## V2 V3 V4 V5 V6 V7 V8 V9
## 0.48365 0.22493 0.31607 -0.01059 0.29963 0.06504 -0.00336 0.02878
## V10 V11 V12 V13 V14
## 0.03930 0.53000 -0.27924 -0.16450 0.36490This means that the first principal component is a linear combination of the variables: -0.144Z2 + 0.245Z3 + 0.002Z4 + 0.239Z5 - 0.142Z6 - 0.395Z7 - 0.423Z8 + 0.299Z9 -0.313Z10 + 0.089Z11 - 0.297Z12 - 0.376Z13 - 0.287*Z14, where Z2, Z3, Z4…Z14 are the standardised versions of the variables V2, V3, V4…V14 (that each have mean of 0 and variance of 1). Note that the square of the loadings sum to 1,
The first principal component has highest (in absolute value) loadings for V8 (-0.423), V7 (-0.395), V13 (-0.376), V10 (-0.313), V12 (-0.297), V14 (-0.287), V9 (0.299), V3 (0.245), and V5 (0.239). The loadings for V8, V7, V13, V10, V12 and V14 are negative, while those for V9, V3, and V5 are positive. Therefore, an interpretation of the first principal component is that it represents a contrast between the concentrations of V8, V7, V13, V10, V12, and V14, and the concentrations of V9, V3 and V5.
Similarly, we can obtain the loadings for the second principal component.
This means that the second principal component is a linear combination of the variables: 0.484Z2 + 0.225Z3 + 0.316Z4 - 0.011Z5 + 0.300Z6 + 0.065Z7 - 0.003Z8 + 0.029Z9 + 0.039Z10 + 0.530Z11 - 0.279Z12 - 0.164Z13 + 0.365*Z14, where Z1, Z2, Z3…Z14 are the standardised versions of variables V2, V3, … V14 that each have mean 0 and variance 1
The second principal component has highest loadings for V11 (0.530), V2 (0.484), V14 (0.365), V4 (0.316), V6 (0.300), V12 (-0.279), and V3 (0.225). The loadings for V11, V2, V14, V4, V6 and V3 are positive, while the loading for V12 is negative. Therefore, an interpretation of the second principal component is that it represents a contrast between the concentrations of V11, V2, V14, V4, V6 and V3, and the concentration of V12. Note that the loadings for V11 (0.530) and V2 (0.484) are the largest, so the contrast is mainly between the concentrations of V11 and V2, and the concentration of V12.
Scatterplots of the Principal Components The values of the principal components are stored in a named element “x” of the variable returned by “prcomp()”. This contains a matrix with the principal components, where the first column in the matrix contains the first principal component, the second column the second component, and so on. Thus, in our example, “wine.pca\(x[,1]" contains the first principal component, and "wine.pca\)x[,2]” contains the second principal component. We can make a scatterplot of the first two principal components, and label the data points with the cultivar that the wine samples come from, by typing
plot(wine.pca$x[,1],wine.pca$x[,2])
# make a scatterplot
text(wine.pca$x[,1],wine.pca$x[,2], wine$V1, cex=0.7, pos=4, col="red")
# add labelsThe scatterplot shows the first principal component on the x-axis, and the second principal component on the y- axis. We can see from the scatterplot that wine samples of cultivar 1 have much lower values of the first principal component than wine samples of cultivar 3. Therefore, the first principal component separates wine samples of cultivars 1 from those of cultivar 3. We can also see that wine samples of cultivar 2 have much higher values of the second principal component than wine samples of cultivars 1 and 3. Therefore, the second principal component separates samples of cultivar 2 from samples of cultivars 1 and 3. Therefore, the first two principal components are reasonably useful for distinguishing wine samples of the three different cultivars. Above, we interpreted the first principal component as a contrast between the concentrations of V8, V7, V13, V10, V12, and V14, and the concentrations of V9, V3 and V5. We can check whether this makes sense in terms of the concentrations of these chemicals in the different cultivars, by printing out the means of the standardised concentration variables in each cultivar, using the “printMeanAndSdByGroup()” function (see above)
Un segundo ejercicio final de analisis multivariante
Los mapas y el analisis multivariante puede ser muy util para tratar datos https://bookdown.org/rdpeng/exdata/
Ejemplo: Polucion del aire respecto a particulas en suspension
https://bookdown.org/rdpeng/exdata/exploratory-graphs.html#air-pollution-in-the-united-states
For the purposes of this chapter (and the rest of this book), we will make a distinction between exploratory graphs and final graphs. This distinction is not a very formal one, but it serves to highlight the fact that graphs are used for many different purposes. Exploratory graphs are usually made very quickly and a lot of them are made in the process of checking out the data.
The goal of making exploratory graphs is usually developing a personal understanding of the data and to prioritize tasks for follow up. Details like axis orientation or legends, while present, are generally cleaned up and prettified if the graph is going to be used for communication later. Often color and plot symbol size are used to convey various dimensions of information.
Inline-style: 
Air Pollution in the United States For this chapter, we will use a simple case study to demonstrate the kinds of simple graphs that can be useful in exploratory analyses. The data we will be using come from the U.S. Environmental Protection Agency (EPA), which is the U.S. government agency that sets national air quality standards for outdoor air pollution. One of the national ambient air quality standards in the U.S. concerns the long-term average level of fine particle pollution, also referred to as PM2.5. Here, the standard says that the “annual mean, averaged over 3 years” cannot exceed 12 micrograms per cubic meter. Data on daily PM2.5 are available from the U.S. EPA web site, or specifically, the EPA Air Quality System web site.
One key question we are interested is: Are there any counties in the U.S. that exceed the national standard for fine particle pollution? This question has important consequences because counties that are found to be in violation of the national standards can face serious legal consequences. In particular, states that have counties in violation of the standards are required to create a State Implementation Plan (SIP) that shows how those counties will come within the national standards within a given period of time.
Otro ejercicio alternativo
Exploracion con datos geoestadisticos
Un buen ejemplo puede encontrarse en
https://stackoverflow.com/questions/43612903/how-to-properly-plot-projected-gridded-data-in-ggplot2
Analisis con redes complejas (Network analysis)
Network theory is the study of graphs as a representation of either symmetric relations or asymmetric relations between discrete objects. In computer science and network science, network theory is a part of graph theory: a network can be defined as a graph in which nodes and/or edges have attributes (e.g. names).
Inline-style: 
Network theory has applications in many disciplines including statistical physics, particle physics, computer science, electrical engineering, biology, economics, finance, operations research, climatology and sociology. Applications of network theory include logistical networks, the World Wide Web, Internet, gene regulatory networks, metabolic networks, social networks, epistemological networks, etc.; see List of network theory topics for more examples.
Ver un ejemplo de red compleja de Gene Ontology
http://cbl-gorilla.cs.technion.ac.il/
Functional analysis of a gene set, using Gorilla:
http://cbl-gorilla.cs.technion.ac.il/GOrilla/vy63cz5g/GOResults.html
Ver introduccion al analisis de redes en: https://www.jessesadler.com/post/network-analysis-with-r/
http://kateto.net/networks-r-igraph
http://kateto.net/network-visualization
Ver curso adjunto de POLNET
http://statmath.wu.ac.at/research/friday/resources_WS0708_SS08/igraph.pdf
Network Analysis and Manipulation using R
What is a network? A network in this context is a graph of interconnected nodes/vertices. Nodes can e.g. be people in a social network, genes in a co-expression network, etc. Nodes are connected via ties/edges.
Inline-style: 
See theory of graphs and adjacency matrices at:
graphs: https://es.wikipedia.org/wiki/Grafo adjacency matrices: https://es.wikipedia.org/wiki/Matriz_de_incidencia
Load required packages tidyverse for general data manipulation and visualization. tidygraph for manipulating and analyzing network graphs. ggraph for visualizing network objects created using the tidygraph package.
library(tidyverse)
library(tidygraph)
library(ggraph)Create network objects Key R functions:
tbl_graph(). Creates a network object from nodes and edges data as_tbl_graph(). Converts network data and objects to a tbl_graph network. Demo data set: phone.call2 data [in the navdata R package], which is a list containing the nodes and the edges list prepared in the chapter @ref(network-visualization-essentials).
Use tbl_graph Create a tbl_graph network object using the phone call data:
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/navdata")
library("navdata")The example is about a famous data set containing the number of daily phone calls between presidents of EU countries.
data("phone.call2")
head(phone.call2)## $nodes
## # A tibble: 16 x 2
## id label
## <int> <chr>
## 1 1 France
## 2 2 Belgium
## 3 3 Germany
## 4 4 Danemark
## 5 5 Croatia
## 6 6 Slovenia
## 7 7 Hungary
## 8 8 Spain
## 9 9 Italy
## 10 10 Netherlands
## 11 11 UK
## 12 12 Austria
## 13 13 Poland
## 14 14 Switzerland
## 15 15 Czech republic
## 16 16 Slovania
##
## $edges
## # A tibble: 18 x 3
## from to weight
## <int> <int> <dbl>
## 1 1 3 9
## 2 2 1 4
## 3 1 8 3
## 4 1 9 4
## 5 1 10 2
## 6 1 11 3
## 7 3 12 2
## 8 3 13 2
## 9 2 3 3
## 10 3 14 2
## 11 3 15 2
## 12 3 10 2
## 13 4 3 2
## 14 5 3 2
## 15 5 16 2
## 16 5 7 2
## 17 6 3 2
## 18 7 16 2.5head(phone.call2)## $nodes
## # A tibble: 16 x 2
## id label
## <int> <chr>
## 1 1 France
## 2 2 Belgium
## 3 3 Germany
## 4 4 Danemark
## 5 5 Croatia
## 6 6 Slovenia
## 7 7 Hungary
## 8 8 Spain
## 9 9 Italy
## 10 10 Netherlands
## 11 11 UK
## 12 12 Austria
## 13 13 Poland
## 14 14 Switzerland
## 15 15 Czech republic
## 16 16 Slovania
##
## $edges
## # A tibble: 18 x 3
## from to weight
## <int> <int> <dbl>
## 1 1 3 9
## 2 2 1 4
## 3 1 8 3
## 4 1 9 4
## 5 1 10 2
## 6 1 11 3
## 7 3 12 2
## 8 3 13 2
## 9 2 3 3
## 10 3 14 2
## 11 3 15 2
## 12 3 10 2
## 13 4 3 2
## 14 5 3 2
## 15 5 16 2
## 16 5 7 2
## 17 6 3 2
## 18 7 16 2.5phone.net <- tbl_graph(
nodes = phone.call2$nodes,
edges = phone.call2$edges,
directed = TRUE
)Visualize a network
Buid the network using ggraph:
ggraph(phone.net, layout = "graphopt") +
geom_edge_link(width = 1, colour = "lightgray") +
geom_node_point(size = 4, colour = "#00AFBB") +
geom_node_text(aes(label = label), repel = TRUE)+
theme_graph() ## example with a real Data-Frame (MTCARS)
## example with a real Data-Frame (MTCARS)
Use as_tbl_graph R function One can also use the as_tbl_graph() function to converts the following data structure and network objects:
data.frame, list and matrix data [R base] igraph network objects [igraph package] network network objects [network pakage] dendrogram and hclust [stats package] Node [data.tree package] phylo and evonet [ape package] graphNEL, graphAM, graphBAM [graph package (in Bioconductor)] In the following example, we’ll create a correlation matrix network graph. The mtcars data set will be used.
Compute the correlation matrix between cars using the corrr package:
Use the mtcars data set Compute the correlation matrix: correlate() Convert the upper triangle to NA: shave() Stretch the correlation data frame into long format Keep only high correlation
library(corrr)
res.cor <- mtcars [, c(1, 3:6)] %>% # (1)
t() %>% correlate() %>% # (2)
shave(upper = TRUE) %>% # (3)
stretch(na.rm = TRUE) %>% # (4)
filter(r >= 0.998) # (5)
res.corCreate the correlation network graph:
set.seed(1)
cor.graph <- as_tbl_graph(res.cor, directed = FALSE)
ggraph(cor.graph) +
geom_edge_link() +
geom_node_point() +
geom_node_text(
aes(label = name), size = 3, repel = TRUE
) +
theme_graph()
Print out a network object
cor.graph## # A tbl_graph: 24 nodes and 59 edges
## #
## # An undirected simple graph with 3 components
## #
## # Node Data: 24 x 1 (active)
## name
## <chr>
## 1 Mazda RX4
## 2 Mazda RX4 Wag
## 3 Datsun 710
## 4 Hornet 4 Drive
## 5 Hornet Sportabout
## 6 Valiant
## # ... with 18 more rows
## #
## # Edge Data: 59 x 3
## from to r
## <int> <int> <dbl>
## 1 1 2 1.00
## 2 1 20 1.00
## 3 1 8 0.999
## # ... with 56 more rowsThe output shows:
a tbl_graph object with 24 nodes and 59 edges. Nodes are the car names and the edges are the correlation links. the first six rows of “Node Data”" and the first three of “Edge Data”. that the Node Data is active. The notion of an active tibble within a tbl_graph object makes it possible to manipulate the data in one tibble at a time. The nodes tibble is activated by default, but you can change which tibble is active with the activate() function.
If you want to rearrange the rows in the edges tibble to list those with the highest “r” first, you could use activate() and then arrange(). For example, type the following R code:
cor.graph %>%
activate(edges) %>%
arrange(desc(r))## # A tbl_graph: 24 nodes and 59 edges
## #
## # An undirected simple graph with 3 components
## #
## # Edge Data: 59 x 3 (active)
## from to r
## <int> <int> <dbl>
## 1 1 2 1.00
## 2 10 11 1.00
## 3 10 12 1.00
## 4 11 12 1.00
## 5 8 9 1.00
## 6 5 18 1.00
## # ... with 53 more rows
## #
## # Node Data: 24 x 1
## name
## <chr>
## 1 Mazda RX4
## 2 Mazda RX4 Wag
## 3 Datsun 710
## # ... with 21 more rowsNetwork graph manipulation
With the tidygraph package, you can easily manipulate the nodes and the edges data in the network graph object using dplyr verbs. For example, you can add new columns or rename columns in the nodes/edges data.
You can also filter and arrange the data. Note that, applying filter()/slice() on node data will remove the edges terminating at the removed nodes.
In this section we’ll manipulate the correlation network graph.
Modify the nodes data: Group the cars by the “cyl” variable (number of cylinders) in the original mtcars data set. We’ll color the cars by groups. Join the group info to the nodes data Rename the column “name”, in the nodes data, to “label” You can use the dplyr verbs as follow:
# Car groups info
cars.group <- data_frame(
name = rownames(mtcars),
cyl = as.factor(mtcars$cyl)
)
# Modify the nodes data
cor.graph <- cor.graph %>%
activate(nodes) %>%
left_join(cars.group, by = "name") %>%
rename(label = name)Modify the edge data. Rename the column “r” to “weight”.
cor.graph <- cor.graph %>%
activate(edges) %>%
rename(weight = r)Display the final modified graphs object:
cor.graph## # A tbl_graph: 24 nodes and 59 edges
## #
## # An undirected simple graph with 3 components
## #
## # Edge Data: 59 x 3 (active)
## from to weight
## <int> <int> <dbl>
## 1 1 2 1.00
## 2 1 20 1.00
## 3 1 8 0.999
## 4 1 9 0.999
## 5 1 11 0.998
## 6 2 20 1.00
## # ... with 53 more rows
## #
## # Node Data: 24 x 2
## label cyl
## <chr> <fct>
## 1 Mazda RX4 6
## 2 Mazda RX4 Wag 6
## 3 Datsun 710 4
## # ... with 21 more rowsVisualize the correlation network.
Change the edges width according to the variable weight Scale the edges width by setting the minimum width to 0.2 and the maximum to 1. Change the color of cars (nodes) according to the grouping variable cyl.
set.seed(1)
ggraph(cor.graph) +
geom_edge_link(aes(width = weight), alpha = 0.2) +
scale_edge_width(range = c(0.2, 1)) +
geom_node_point(aes(color = cyl), size = 2) +
geom_node_text(aes(label = label), size = 3, repel = TRUE) +
theme_graph()
Network analysis
In this sections, we described methods for detecting important or central entities in a network graph. We’ll also introduce how to detect community (or cluster) in a network.
Centrality Centrality is an important concept when analyzing network graph. The centrality of a node / edge measures how central (or important) is a node or edge in the network.
We consider an entity important, if he has connections to many other entities. Centrality describes the number of edges that are connected to nodes.
There many types of scores that determine centrality. One of the famous ones is the pagerank algorithm that was powering Google Search in the beginning.
Examples of common approaches of measuring centrality include:
betweenness centrality. The betweenness centrality for each nodes is the number of the shortest paths that pass through the nodes.
closeness centrality. Closeness centrality measures how many steps is required to access every other nodes from a given nodes. It describes the distance of a node to all other nodes. The more central a node is, the closer it is to all other nodes.
eigenvector centrality. A node is important if it is linked to by other important nodes. The centrality of each node is proportional to the sum of the centralities of those nodes to which it is connected. In general, nodes with high eigenvector centralities are those which are linked to many other nodes which are, in turn, connected to many others (and so on).
Hub and authority centarlities are generalization of eigenvector centrality. A high hub node points to many good authorities and a high authority node receives from many good hubs.
The tidygraph package contains more than 10 centrality measures, prefixed with the term centrality_. These measures include:
#centrality_authority()
#centrality_betweenness()
#centrality_closeness()
#centrality_hub()
#centrality_pagerank()
#centrality_eigen()
#centrality_edge_betweenness()All of these centrality functions returns a numeric vector matching the nodes (or edges in the case of `centrality_edge_betweenness()).
In the following examples, we’ll use the phone call network graph. We’ll change the color and the size of nodes according to their values of centrality.
set.seed(123)
phone.net %>%
activate(nodes) %>%
mutate(centrality = centrality_authority()) %>%
ggraph(layout = "graphopt") +
geom_edge_link(width = 1, colour = "lightgray") +
geom_node_point(aes(size = centrality, colour = centrality)) +
geom_node_text(aes(label = label), repel = TRUE)+
scale_color_gradient(low = "yellow", high = "red")+
theme_graph()
Clustering
Clustering is a common operation in network analysis and it consists of grouping nodes based on the graph topology.
It’s sometimes referred to as community detection based on its commonality in social network analysis.
Many clustering algorithms from are available in the tidygraph package and prefixed with the term group_. These include:
Infomap community finding. It groups nodes by minimizing the expected description length of a random walker trajectory. R function: group_infomap() Community structure detection based on edge betweenness. It groups densely connected nodes. R function: group_edge_betweenness(). In the following example, we’ll use the correlation network graphs to detect clusters or communities:
set.seed(123)
cor.graph %>%
activate(nodes) %>%
mutate(community = as.factor(group_infomap())) %>%
ggraph(layout = "graphopt") +
geom_edge_link(width = 1, colour = "lightgray") +
geom_node_point(aes(colour = community), size = 4) +
geom_node_text(aes(label = label), repel = TRUE)+
theme_graph()
see more at https://datascienceplus.com/network-analysis-of-game-of-thrones/
COMPLEX NETWORKS IN BIOLOGY
SEE https://bioconductor.org/help/publications/book-chapters/MiMB/
Categorical variables
Datos y script en parte procedentes de curso MSIO Klaus Langohrt
Frequency table
Example of the population of USA: estudio de la esperanza de vida, nivel de ingresos y temperatura
load("GrB_RLecture8.RData")
#head(states)
table(states$reg)##
## Northeast South North Central West
## 9 16 12 13summary(states$reg) # Returns a frequency table if the variable is a factor!## Northeast South North Central West
## 9 16 12 13Maybe a bit nicer and more informative
library(Hmisc)
describe(states$reg)## states$reg : Region
## n missing distinct
## 50 0 4
##
## Value Northeast South North Central West
## Frequency 9 16 12 13
## Proportion 0.18 0.32 0.24 0.26More and best alternatives for frequency tables
- Function ctab (Package catspec)
#install.packages("catspec")
library(catspec)
ctab(states$reg)## Count Total %
## Var1
## Northeast 9 18
## South 16 32
## North Central 12 24
## West 13 26- Function stat.table (Epi)
# install.packages("Epi")
library(Epi)
stat.table(list(reg), data = states)## ------------------------
## reg count()
## ------------------------
## Northeast 9
## South 16
## North Central 12
## West 13
## ------------------------stat.table(list(Region = reg), list(N = count(), "%" = percent(reg)),
data = states, margins = T)## --------------------------------
## Region N %
## --------------------------------
## Northeast 9 18.0
## South 16 32.0
## North Central 12 24.0
## West 13 26.0
##
## Total 50 100.0
## --------------------------------stat.table(list(Region = reg), list(N = count(), "%" = percent(reg),
"Av. income" = mean(inco)),
data = states, margins = T)## ----------------------------------------
## Region N % Av.
## income
## ----------------------------------------
## Northeast 9 18.0 4570.22
## South 16 32.0 4011.94
## North Central 12 24.0 4611.08
## West 13 26.0 4702.62
##
## Total 50 100.0 4435.80
## ----------------------------------------- Function freq (descr)
#install.packages("descr")
library(descr)
freq(states$reg)
## Region
## Frequency Percent
## Northeast 9 18
## South 16 32
## North Central 12 24
## West 13 26
## Total 50 100freq(states$reg, plot = F)## Region
## Frequency Percent
## Northeast 9 18
## South 16 32
## North Central 12 24
## West 13 26
## Total 50 100What if there are missing data?
reg <- states$reg
summary(reg)## Northeast South North Central West
## 9 16 12 13Missing values are represented differently in each table
library(catspec)
ctab(reg, addmargins = T)## Count Total %
## reg
## Northeast 9 18
## South 16 32
## North Central 12 24
## West 13 26
## Sum 50 100stat.table(list(Region = reg), list(N = count(), "%" = percent(reg)), margins = T)## --------------------------------
## Region N %
## --------------------------------
## Northeast 9 18.0
## South 16 32.0
## North Central 12 24.0
## West 13 26.0
##
## Total 50 100.0
## --------------------------------freq(reg, plot = F)## Region
## Frequency Percent
## Northeast 9 18
## South 16 32
## North Central 12 24
## West 13 26
## Total 50 100| How to create an ordinal variable from a numeric one? |
|---|
| Using function cut2 from package Hmisc |
cut2(states$inco, c(4000, 4500, 5000))## Income
## [1] [3098,4000) [5000,6315] [4500,5000) [3098,4000) [5000,6315] [4500,5000)
## [7] [5000,6315] [4500,5000) [4500,5000) [4000,4500) [4500,5000) [4000,4500)
## [13] [5000,6315] [4000,4500) [4500,5000) [4500,5000) [3098,4000) [3098,4000)
## [19] [3098,4000) [5000,6315] [4500,5000) [4500,5000) [4500,5000) [3098,4000)
## [25] [4000,4500) [4000,4500) [4500,5000) [5000,6315] [4000,4500) [5000,6315]
## [31] [3098,4000) [4500,5000) [3098,4000) [5000,6315] [4500,5000) [3098,4000)
## [37] [4500,5000) [4000,4500) [4500,5000) [3098,4000) [4000,4500) [3098,4000)
## [43] [4000,4500) [4000,4500) [3098,4000) [4500,5000) [4500,5000) [3098,4000)
## [49] [4000,4500) [4500,5000)
## Levels: [3098,4000) [4000,4500) [4500,5000) [5000,6315]states$inco2 <- cut2(states$inco, c(4000, 4500, 5000))
head(states)summary(states)## pop inco illi lifex murd
## Min. : 365 Min. :3098 Min. :0.500 Min. :68.0 Min. : 1.40
## 1st Qu.: 1080 1st Qu.:3993 1st Qu.:0.625 1st Qu.:70.1 1st Qu.: 4.35
## Median : 2838 Median :4519 Median :0.950 Median :70.7 Median : 6.85
## Mean : 4246 Mean :4436 Mean :1.170 Mean :70.9 Mean : 7.38
## 3rd Qu.: 4968 3rd Qu.:4814 3rd Qu.:1.575 3rd Qu.:71.9 3rd Qu.:10.68
## Max. :21198 Max. :6315 Max. :2.800 Max. :73.6 Max. :15.10
## hsg fro area reg
## Min. :37.8 Min. : 0.0 Min. : 1049 Northeast : 9
## 1st Qu.:48.0 1st Qu.: 66.2 1st Qu.: 36985 South :16
## Median :53.2 Median :114.5 Median : 54277 North Central:12
## Mean :53.1 Mean :104.5 Mean : 70736 West :13
## 3rd Qu.:59.1 3rd Qu.:139.8 3rd Qu.: 81162
## Max. :67.3 Max. :188.0 Max. :566432
## inco2
## [3098,4000):13
## [4000,4500):11
## [4500,5000):18
## [5000,6315]: 8
##
## levels(states$inco2)## [1] "[3098,4000)" "[4000,4500)" "[4500,5000)" "[5000,6315]"levels(states$inco2)[c(1, 4)] <- c("< 4000", ">= 5000")
levels(states$inco2)## [1] "< 4000" "[4000,4500)" "[4500,5000)" ">= 5000"# Optional: label and units for the new variable
label(states$inco2) <- "Income"
units(states$inco2) <- "Dollar"
describe(states)## states
##
## 10 Variables 50 Observations
## --------------------------------------------------------------------------------
## pop : Population [In 1000s]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 50 1 4246 4364 520.2 632.3
## .25 .50 .75 .90 .95
## 1079.5 2838.5 4968.5 10781.2 12067.3
##
## lowest : 365 376 472 579 590, highest: 11197 11860 12237 18076 21198
## --------------------------------------------------------------------------------
## inco : Income [Dollars]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 50 1 4436 692.7 3570 3623
## .25 .50 .75 .90 .95
## 3993 4519 4814 5118 5271
##
## lowest : 3098 3378 3545 3601 3617, highest: 5149 5237 5299 5348 6315
## --------------------------------------------------------------------------------
## illi : Illiteracy [Percentage of population]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 20 0.989 1.17 0.674 0.545 0.600
## .25 .50 .75 .90 .95
## 0.625 0.950 1.575 2.110 2.255
##
## Value 0.5 0.6 0.7 0.8 0.9 1.0 1.1 1.3 1.4 1.5 1.6 1.7 1.8
## Frequency 3 10 5 3 4 1 5 2 3 1 1 1 2
## Proportion 0.06 0.20 0.10 0.06 0.08 0.02 0.10 0.04 0.06 0.02 0.02 0.02 0.04
##
## Value 1.9 2.0 2.1 2.2 2.3 2.4 2.8
## Frequency 2 1 1 2 1 1 1
## Proportion 0.04 0.02 0.02 0.04 0.02 0.02 0.02
## --------------------------------------------------------------------------------
## lifex : Life expectance [Years]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 47 1 70.88 1.537 68.64 69.05
## .25 .50 .75 .90 .95
## 70.12 70.67 71.89 72.58 72.85
##
## lowest : 67.96 68.09 68.54 68.76 69.03, highest: 72.60 72.78 72.90 72.96 73.60
## --------------------------------------------------------------------------------
## murd : Murder rate [per 100000]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 44 1 7.378 4.277 2.30 2.67
## .25 .50 .75 .90 .95
## 4.35 6.85 10.67 11.66 12.88
##
## lowest : 1.4 1.7 2.3 2.4 2.7, highest: 12.2 12.5 13.2 13.9 15.1
## --------------------------------------------------------------------------------
## hsg : High school graduates (%)
## n missing distinct Info Mean Gmd .05 .10
## 50 0 47 1 53.11 9.24 39.13 40.96
## .25 .50 .75 .90 .95
## 48.05 53.25 59.15 62.96 64.61
##
## lowest : 37.8 38.5 39.9 40.6 41.0, highest: 63.5 63.9 65.2 66.7 67.3
## --------------------------------------------------------------------------------
## fro : Mean number of days with minimum temperature below freezing
## n missing distinct Info Mean Gmd .05 .10
## 50 0 43 1 104.5 59.79 13.35 20.00
## .25 .50 .75 .90 .95
## 66.25 114.50 139.75 168.40 173.55
##
## lowest : 0 11 12 15 20, highest: 172 173 174 186 188
## --------------------------------------------------------------------------------
## area : Area [Square miles]
## n missing distinct Info Mean Gmd .05 .10
## 50 0 50 1 70736 66622 5565 7796
## .25 .50 .75 .90 .95
## 36985 54277 81163 114217 151513
##
## lowest : 1049 1982 4862 6425 7521, highest: 121412 145587 156361 262134 566432
## --------------------------------------------------------------------------------
## reg : Region
## n missing distinct
## 50 0 4
##
## Value Northeast South North Central West
## Frequency 9 16 12 13
## Proportion 0.18 0.32 0.24 0.26
## --------------------------------------------------------------------------------
## inco2 : Income [Dollar]
## n missing distinct
## 50 0 4
##
## Value < 4000 [4000,4500) [4500,5000) >= 5000
## Frequency 13 11 18 8
## Proportion 0.26 0.22 0.36 0.16
## --------------------------------------------------------------------------------For the same purpose, see, also, functions cut, ifelse, recode (paquete memisc), etc.
Diversity of categorical data
How to measure the variability in categorical data?
#ejemplo de vector categorico
fac <- factor(c("C", "D", "A", "D", "E", "D", "C", "E", "E", "B", "E"),
levels=c(LETTERS[1:5], "Q"))
P <- nlevels(fac)
(Fj <- prop.table(table(fac)))## fac
## A B C D E Q
## 0.09091 0.09091 0.18182 0.27273 0.36364 0.00000fac## [1] C D A D E D C E E B E
## Levels: A B C D E QUse the diversity index (Shannon index) to measure the variability/dispersion over a sample
library(vegan)
shannonIdx <- diversity(Fj, index="shannon")
(H <- (1/log(P)) * shannonIdx)## [1] 0.8194Ver Shannon index en:
B. Bivariate descriptive analysis
Both variables are numeric: Correlation
with(states, cor(murd, lifex))## [1] -0.7808with(states, cor(murd, lifex, method = "spearman"))## [1] -0.7802cor(states[1:8])## pop inco illi lifex murd hsg fro area
## pop 1.00000 0.2082 0.10762 -0.06805 0.3436 -0.09849 -0.33215 0.02254
## inco 0.20823 1.0000 -0.43708 0.34026 -0.2301 0.61993 0.22628 0.36332
## illi 0.10762 -0.4371 1.00000 -0.58848 0.7030 -0.65719 -0.67195 0.07726
## lifex -0.06805 0.3403 -0.58848 1.00000 -0.7808 0.58222 0.26207 -0.10733
## murd 0.34364 -0.2301 0.70298 -0.78085 1.0000 -0.48797 -0.53888 0.22839
## hsg -0.09849 0.6199 -0.65719 0.58222 -0.4880 1.00000 0.36678 0.33354
## fro -0.33215 0.2263 -0.67195 0.26207 -0.5389 0.36678 1.00000 0.05923
## area 0.02254 0.3633 0.07726 -0.10733 0.2284 0.33354 0.05923 1.00000round(cor(states[1:8]), 3)## pop inco illi lifex murd hsg fro area
## pop 1.000 0.208 0.108 -0.068 0.344 -0.098 -0.332 0.023
## inco 0.208 1.000 -0.437 0.340 -0.230 0.620 0.226 0.363
## illi 0.108 -0.437 1.000 -0.588 0.703 -0.657 -0.672 0.077
## lifex -0.068 0.340 -0.588 1.000 -0.781 0.582 0.262 -0.107
## murd 0.344 -0.230 0.703 -0.781 1.000 -0.488 -0.539 0.228
## hsg -0.098 0.620 -0.657 0.582 -0.488 1.000 0.367 0.334
## fro -0.332 0.226 -0.672 0.262 -0.539 0.367 1.000 0.059
## area 0.023 0.363 0.077 -0.107 0.228 0.334 0.059 1.000If interested in a confidence interval
with(states, cor.test(inco, illi))##
## Pearson's product-moment correlation
##
## data: inco and illi
## t = -3.4, df = 48, p-value = 0.002
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.6378 -0.1807
## sample estimates:
## cor
## -0.4371Little exercise: Which pair of variables shows the largest correlation (in absolute value)?
Both variables are categorical: contingency tables
Very simple contingency tables
with(states, table(reg, inco2))## inco2
## reg < 4000 [4000,4500) [4500,5000) >= 5000
## Northeast 2 2 3 2
## South 10 2 3 1
## North Central 0 4 6 2
## West 1 3 6 3tab <- with(states, table(reg, inco2))
tab## inco2
## reg < 4000 [4000,4500) [4500,5000) >= 5000
## Northeast 2 2 3 2
## South 10 2 3 1
## North Central 0 4 6 2
## West 1 3 6 3Relative (conditional) frequencies
prop.table(tab)## inco2
## reg < 4000 [4000,4500) [4500,5000) >= 5000
## Northeast 0.04 0.04 0.06 0.04
## South 0.20 0.04 0.06 0.02
## North Central 0.00 0.08 0.12 0.04
## West 0.02 0.06 0.12 0.06round(prop.table(tab, 1)*100, 1)## inco2
## reg < 4000 [4000,4500) [4500,5000) >= 5000
## Northeast 22.2 22.2 33.3 22.2
## South 62.5 12.5 18.8 6.2
## North Central 0.0 33.3 50.0 16.7
## West 7.7 23.1 46.2 23.1Somewhat nicer and more informative (a) Function ctab (Package catspec)
with(states, ctab(reg, inco2))## inco2 < 4000 [4000,4500) [4500,5000) >= 5000
## reg
## Northeast 2 2 3 2
## South 10 2 3 1
## North Central 0 4 6 2
## West 1 3 6 3with(states, ctab(reg, inco2, type = c("n", "r"), addmargins = T))## inco2 < 4000 [4000,4500) [4500,5000) >= 5000 Sum
## reg
## Northeast Count 2.00 2.00 3.00 2.00 9.00
## Row % 22.22 22.22 33.33 22.22 100.00
## South Count 10.00 2.00 3.00 1.00 16.00
## Row % 62.50 12.50 18.75 6.25 100.00
## North Central Count 0.00 4.00 6.00 2.00 12.00
## Row % 0.00 33.33 50.00 16.67 100.00
## West Count 1.00 3.00 6.00 3.00 13.00
## Row % 7.69 23.08 46.15 23.08 100.00
## Sum Count 13.00 11.00 18.00 8.00 50.00
## Row % 92.41 91.13 148.24 68.22 400.00- Function stat.table (Epi)
stat.table(list(Region = reg, Income = inco2), list(N = count(),
"%" = percent(inco2)), data = states)## --------------------------------------------------------
## -----------------Income------------------
## Region < 4000 [4000,4500) [4500,5000) >= 5000
## --------------------------------------------------------
## Northeast 2 2 3 2
## 22.2 22.2 33.3 22.2
##
## South 10 2 3 1
## 62.5 12.5 18.8 6.2
##
## North Central 0 4 6 2
## 0.0 33.3 50.0 16.7
##
## West 1 3 6 3
## 7.7 23.1 46.2 23.1
## --------------------------------------------------------stat.table(list(Region = reg, Income = inco2), list(N = count(),
"%" = percent(inco2)), data = states, margins = T)## ----------------------------------------------------------------
## ---------------------Income----------------------
## Region < 4000 [4000,4500) [4500,5000) >= 5000 Total
## ----------------------------------------------------------------
## Northeast 2 2 3 2 9
## 22.2 22.2 33.3 22.2 100.0
##
## South 10 2 3 1 16
## 62.5 12.5 18.8 6.2 100.0
##
## North Central 0 4 6 2 12
## 0.0 33.3 50.0 16.7 100.0
##
## West 1 3 6 3 13
## 7.7 23.1 46.2 23.1 100.0
##
##
## Total 13 11 18 8 50
## 26.0 22.0 36.0 16.0 100.0
## ----------------------------------------------------------------- Function CrossTable (descr)
with(states, CrossTable(reg, inco2))## Cell Contents
## |-------------------------|
## | N |
## | Chi-square contribution |
## | N / Row Total |
## | N / Col Total |
## | N / Table Total |
## |-------------------------|
##
## =====================================================================
## inco2
## reg < 4000 [4000,4500) [4500,5000) >= 5000 Total
## ---------------------------------------------------------------------
## Northeast 2 2 3 2 9
## 0.049 0.000 0.018 0.218
## 0.222 0.222 0.333 0.222 0.180
## 0.154 0.182 0.167 0.250
## 0.04 0.04 0.06 0.04
## ---------------------------------------------------------------------
## South 10 2 3 1 16
## 8.198 0.656 1.322 0.951
## 0.625 0.125 0.188 0.062 0.320
## 0.769 0.182 0.167 0.125
## 0.20 0.04 0.06 0.02
## ---------------------------------------------------------------------
## North Central 0 4 6 2 12
## 3.120 0.701 0.653 0.003
## 0.000 0.333 0.500 0.167 0.240
## 0.000 0.364 0.333 0.250
## 0.00 0.08 0.12 0.04
## ---------------------------------------------------------------------
## West 1 3 6 3 13
## 1.676 0.007 0.372 0.407
## 0.077 0.231 0.462 0.231 0.260
## 0.077 0.273 0.333 0.375
## 0.02 0.06 0.12 0.06
## ---------------------------------------------------------------------
## Total 13 11 18 8 50
## 0.26 0.22 0.36 0.16
## =====================================================================with(states, CrossTable(reg, inco2, prop.t = F, prop.c = F,
prop.chisq = F, format = "SPSS", dnn = c("Region", "Income")))## Cell Contents
## |-------------------------|
## | Count |
## | Row Percent |
## |-------------------------|
##
## =====================================================================
## Income
## Region < 4000 [4000,4500) [4500,5000) >= 5000 Total
## ---------------------------------------------------------------------
## Northeast 2 2 3 2 9
## 22.2% 22.2% 33.3% 22.2% 18.0%
## ---------------------------------------------------------------------
## South 10 2 3 1 16
## 62.5% 12.5% 18.8% 6.2% 32.0%
## ---------------------------------------------------------------------
## North Central 0 4 6 2 12
## 0.0% 33.3% 50.0% 16.7% 24.0%
## ---------------------------------------------------------------------
## West 1 3 6 3 13
## 7.7% 23.1% 46.2% 23.1% 26.0%
## ---------------------------------------------------------------------
## Total 13 11 18 8 50
## =====================================================================Note that a table can be stored as an object
tabla <- with(states, CrossTable(reg, inco2, prop.t = F, prop.c = F,
prop.chisq = F, format = "SPSS", dnn = c("Region", "Income")))
str(tabla)## List of 35
## $ tab : 'table' int [1:4, 1:4] 2 10 0 1 2 2 4 3 3 3 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ x: chr [1:4] "Northeast" "South" "North Central" "West"
## .. ..$ y: chr [1:4] "< 4000" "[4000,4500)" "[4500,5000)" ">= 5000"
## $ prop.row : 'table' num [1:4, 1:4] 0.2222 0.625 0 0.0769 0.2222 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ x: chr [1:4] "Northeast" "South" "North Central" "West"
## .. ..$ y: chr [1:4] "< 4000" "[4000,4500)" "[4500,5000)" ">= 5000"
## $ prop.col : logi NA
## $ prop.tbl : logi NA
## $ gt : int 50
## $ rs : Named num [1:4] 9 16 12 13
## ..- attr(*, "names")= chr [1:4] "Northeast" "South" "North Central" "West"
## $ cs : Named num [1:4] 13 11 18 8
## ..- attr(*, "names")= chr [1:4] "< 4000" "[4000,4500)" "[4500,5000)" ">= 5000"
## $ total.n : int 50
## $ chisq : logi FALSE
## $ CST : logi NA
## $ chisq.corr : logi NA
## $ fisher.ts : logi NA
## $ fisher.lt : logi NA
## $ fisher.gt : logi NA
## $ print.mcnemar: logi FALSE
## $ mcnemar : logi NA
## $ mcnemar.corr : logi NA
## $ asr : logi NA
## $ RowData : chr "Region"
## $ ColData : chr "Income"
## $ digits :List of 4
## ..$ expected: num 1
## ..$ prop : num 3
## ..$ percent : num 1
## ..$ others : num 3
## $ max.width : logi NA
## $ vector.x : logi FALSE
## $ expected : logi FALSE
## $ prop.chisq : logi FALSE
## $ resid : logi FALSE
## $ sresid : logi FALSE
## $ asresid : logi FALSE
## $ format : chr "SPSS"
## $ cell.layout : logi TRUE
## $ row.labels : logi FALSE
## $ percent : logi TRUE
## $ total.r : logi TRUE
## $ total.c : logi TRUE
## $ t : 'table' int [1:4, 1:4] 2 10 0 1 2 2 4 3 3 3 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ x: chr [1:4] "Northeast" "South" "North Central" "West"
## .. ..$ y: chr [1:4] "< 4000" "[4000,4500)" "[4500,5000)" ">= 5000"
## - attr(*, "class")= chr "CrossTable"class(tabla)## [1] "CrossTable"typeof(tabla)## [1] "list"tabla$prop.row## y
## x < 4000 [4000,4500) [4500,5000) >= 5000
## Northeast 0.22222 0.22222 0.33333 0.22222
## South 0.62500 0.12500 0.18750 0.06250
## North Central 0.00000 0.33333 0.50000 0.16667
## West 0.07692 0.23077 0.46154 0.23077Numeric variables vs. a categorical one
Function tapply
with(states, tapply(lifex, reg, mean))## Northeast South North Central West
## 71.26 69.71 71.77 71.23with(states, tapply(lifex, inco2, summary))## $`< 4000`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 68.0 69.0 70.1 69.8 70.4 71.6
##
## $`[4000,4500)`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 68.5 70.6 70.9 71.1 72.0 72.9
##
## $`[4500,5000)`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 70.1 70.6 71.8 71.5 72.5 73.6
##
## $`>= 5000`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 69.0 69.9 70.6 70.8 71.9 72.8Function by
with(states, by(lifex, reg, mean))## reg: Northeast
## [1] 71.26
## ------------------------------------------------------------
## reg: South
## [1] 69.71
## ------------------------------------------------------------
## reg: North Central
## [1] 71.77
## ------------------------------------------------------------
## reg: West
## [1] 71.23with(states, by(lifex, inco2, summary))## inco2: < 4000
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 68.0 69.0 70.1 69.8 70.4 71.6
## ------------------------------------------------------------
## inco2: [4000,4500)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 68.5 70.6 70.9 71.1 72.0 72.9
## ------------------------------------------------------------
## inco2: [4500,5000)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 70.1 70.6 71.8 71.5 72.5 73.6
## ------------------------------------------------------------
## inco2: >= 5000
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 69.0 69.9 70.6 70.8 71.9 72.8with(states, by(states, reg, summary))## reg: Northeast
## pop inco illi lifex murd
## Min. : 472 Min. :3694 Min. :0.6 Min. :70.4 Min. : 2.40
## 1st Qu.: 931 1st Qu.:4281 1st Qu.:0.7 1st Qu.:70.5 1st Qu.: 3.10
## Median : 3100 Median :4558 Median :1.1 Median :71.2 Median : 3.30
## Mean : 5495 Mean :4570 Mean :1.0 Mean :71.3 Mean : 4.72
## 3rd Qu.: 7333 3rd Qu.:4903 3rd Qu.:1.1 3rd Qu.:71.8 3rd Qu.: 5.50
## Max. :18076 Max. :5348 Max. :1.4 Max. :72.5 Max. :10.90
## hsg fro area reg inco2
## Min. :46.4 Min. : 82 Min. : 1049 Northeast :9 < 4000 :2
## 1st Qu.:52.5 1st Qu.:115 1st Qu.: 7521 South :0 [4000,4500):2
## Median :54.7 Median :127 Median : 9027 North Central:0 [4500,5000):3
## Mean :54.0 Mean :133 Mean :18141 West :0 >= 5000 :2
## 3rd Qu.:57.1 3rd Qu.:161 3rd Qu.:30920
## Max. :58.5 Max. :174 Max. :47831
## ------------------------------------------------------------
## reg: South
## pop inco illi lifex murd
## Min. : 579 Min. :3098 Min. :0.90 Min. :68.0 Min. : 6.20
## 1st Qu.: 2622 1st Qu.:3622 1st Qu.:1.38 1st Qu.:69.0 1st Qu.: 9.25
## Median : 3710 Median :3848 Median :1.75 Median :70.1 Median :10.85
## Mean : 4208 Mean :4012 Mean :1.74 Mean :69.7 Mean :10.58
## 3rd Qu.: 4944 3rd Qu.:4316 3rd Qu.:2.12 3rd Qu.:70.3 3rd Qu.:12.28
## Max. :12237 Max. :5299 Max. :2.80 Max. :71.4 Max. :15.10
## hsg fro area reg
## Min. :37.8 Min. : 11.0 Min. : 1982 Northeast : 0
## 1st Qu.:40.4 1st Qu.: 46.2 1st Qu.: 37294 South :16
## Median :41.7 Median : 67.5 Median : 46113 North Central: 0
## Mean :44.3 Mean : 64.6 Mean : 54605 West : 0
## 3rd Qu.:48.8 3rd Qu.: 87.5 3rd Qu.: 52481
## Max. :54.6 Max. :103.0 Max. :262134
## inco2
## < 4000 :10
## [4000,4500): 2
## [4500,5000): 3
## >= 5000 : 1
##
##
## ------------------------------------------------------------
## reg: North Central
## pop inco illi lifex murd
## Min. : 637 Min. :4167 Min. :0.5 Min. :70.1 Min. : 1.40
## 1st Qu.: 2096 1st Qu.:4466 1st Qu.:0.6 1st Qu.:70.8 1st Qu.: 2.30
## Median : 4255 Median :4594 Median :0.7 Median :72.3 Median : 3.75
## Mean : 4803 Mean :4611 Mean :0.7 Mean :71.8 Mean : 5.28
## 3rd Qu.: 6262 3rd Qu.:4694 3rd Qu.:0.8 3rd Qu.:72.6 3rd Qu.: 7.88
## Max. :11197 Max. :5107 Max. :0.9 Max. :73.0 Max. :11.10
## hsg fro area reg
## Min. :48.8 Min. :108 Min. :36097 Northeast : 0
## 1st Qu.:52.8 1st Qu.:124 1st Qu.:55427 South : 0
## Median :53.2 Median :133 Median :62906 North Central:12
## Mean :54.5 Mean :139 Mean :62652 West : 0
## 3rd Qu.:58.0 3rd Qu.:152 3rd Qu.:76087
## Max. :59.9 Max. :186 Max. :81787
## inco2
## < 4000 :0
## [4000,4500):4
## [4500,5000):6
## >= 5000 :2
##
##
## ------------------------------------------------------------
## reg: West
## pop inco illi lifex murd
## Min. : 365 Min. :3601 Min. :0.50 Min. :69.0 Min. : 4.20
## 1st Qu.: 746 1st Qu.:4347 1st Qu.:0.60 1st Qu.:70.3 1st Qu.: 5.00
## Median : 1144 Median :4660 Median :0.60 Median :71.7 Median : 6.80
## Mean : 2915 Mean :4703 Mean :1.02 Mean :71.2 Mean : 7.21
## 3rd Qu.: 2284 3rd Qu.:4963 3rd Qu.:1.50 3rd Qu.:72.1 3rd Qu.: 9.70
## Max. :21198 Max. :6315 Max. :2.20 Max. :73.6 Max. :11.50
## hsg fro area reg
## Min. :55.2 Min. : 0 Min. : 6425 Northeast : 0
## 1st Qu.:59.5 1st Qu.: 32 1st Qu.: 82677 South : 0
## Median :62.6 Median :126 Median :103766 North Central: 0
## Mean :62.0 Mean :102 Mean :134463 West :13
## 3rd Qu.:63.9 3rd Qu.:155 3rd Qu.:121412
## Max. :67.3 Max. :188 Max. :566432
## inco2
## < 4000 :1
## [4000,4500):3
## [4500,5000):6
## >= 5000 :3
##
## Function summaryBy(doBy)
library(doBy)
summaryBy(lifex ~ reg, states, FUN = mean)summaryBy(lifex ~ reg, states, FUN = c(mean, sd))summaryBy(illi ~ reg + inco2, states, FUN = summary)summaryBy(lifex + murd~reg, states, FUN = c(mean, sd))sumby <- summaryBy(lifex ~ reg, states, FUN = c(mean, sd, median, min, max))
sumbynames(sumby) <- c("Region", "Mean", "St.Dev.", "Median", "Min.", "Max.")
print(sumby, digits = 3)## Region Mean St.Dev. Median Min. Max.
## 1 Northeast 71.3 0.744 71.2 70.4 72.5
## 2 South 69.7 1.022 70.1 68.0 71.4
## 3 North Central 71.8 1.037 72.3 70.1 73.0
## 4 West 71.2 1.352 71.7 69.0 73.6But, what if there is a NA in any of the variables Assume we have two missing data in variable lifex
states$lifex[c(1, 50)] <- NA
with(states, tapply(lifex, reg, mean)) # returns two missing values## Northeast South North Central West
## 71.26 NA 71.77 NAMultivariate categorical analysis (correspondance analysis)
Correspondence Analysis (CA) is a multivariate graphical technique designed to explore relationships among categorical variables. Epidemiologists frequently collect data on multiple categorical variables with to the goal of examining associations amongst these variables. Nevertheless, despite its usefulness in this context, CA appears to be an underused technique in epidemiology. The objective of this paper is to present the utility of CA in an epidemiological context.
Correspondence analysis (CA) is an extension of principal component analysis suited to explore relationships among qualitative variables (or categorical data). Like principal component analysis, it provides a solution for summarizing and visualizing data set in two-dimension plots.
Here, we describe the simple correspondence analysis, which is used to analyze frequencies formed by two categorical data, a data table known as contengency table. It provides factor scores (coordinates) for both row and column points of contingency table. These coordinates are used to visualize graphically the association between row and column elements in the contingency table.
When analyzing a two-way contingency table, a typical question is whether certain row elements are associated with some elements of column elements. Correspondence analysis is a geometric approach for visualizing the rows and columns of a two-way contingency table as points in a low-dimensional space, such that the positions of the row and column points are consistent with their associations in the table. The aim is to have a global view of the data that is useful for interpretation.
In the current chapter, we’ll show how to compute and interpret correspondence analysis using two R packages: i) FactoMineR for the analysis and ii) factoextra for data visualization. Additionally, we’ll show how to reveal the most important variables that explain the variations in a data set. We continue by explaining how to apply correspondence analysis using supplementary rows and columns. This is important, if you want to make predictions with CA. The last sections of this guide describe also how to filter CA result in order to keep only the most contributing variables. Finally, we’ll see how to deal with outliers.
Examples at Correspondence Analysis (CA) is a multivariate graphical technique designed to explore relationships among categorical variables. Epidemiologists frequently collect data on multiple categorical variables with to the goal of examining associations amongst these variables. Nevertheless, despite its usefulness in this context, CA appears to be an underused technique in epidemiology. The objective of this paper is to present the utility of CA in an epidemiological context. package for R
http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005752